
{kind=link}
The SQL Server 11.0 launch (code named “Denali”) introduces a brand new information warehouse question acceleration characteristic primarily based on a brand new kind of index referred to as the columnstore. Columnstore indexing is formally introduced in SQL Server 2012. It’s working primarily based on xVelocity reminiscence optimised expertise and it improves information warehouse question efficiency considerably. As a result of the truth that information warehousing, choice assist methods and enterprise intelligence purposes are rising in a short time, we’d like to have the ability to learn and course of very massive information units shortly and precisely into helpful data and data. Columnstore index expertise is very acceptable for information warehousing information units. It improves the widespread information warehousing queries’ efficiency considerably.
Columnstore index is storing information for every column and joins all of the columns to finish the index. There are a lot of benefits of utilizing columnstore indexing compared with the standard rowstore indexing. The time period “rowstore” is utilizing to explain both a heap or a B-tree that comprises a number of rows per web page. As columnstore indexing is fairly new, it has some restrictions and limitations. So, you need to be conscious of these limitations when you’re planning to implement columnstore index in your information warehouse. On this article we’ll focus on in regards to the beneath subjects:
§ How columnstore index works?
§ Advantages of utilizing columnstore indexes
§ Restrictions of columnstore indexes
§ Easy methods to create a SQL Server columnstore index?
§ Planning for creating columnstore index
§ Selecting columns for a columnstore index
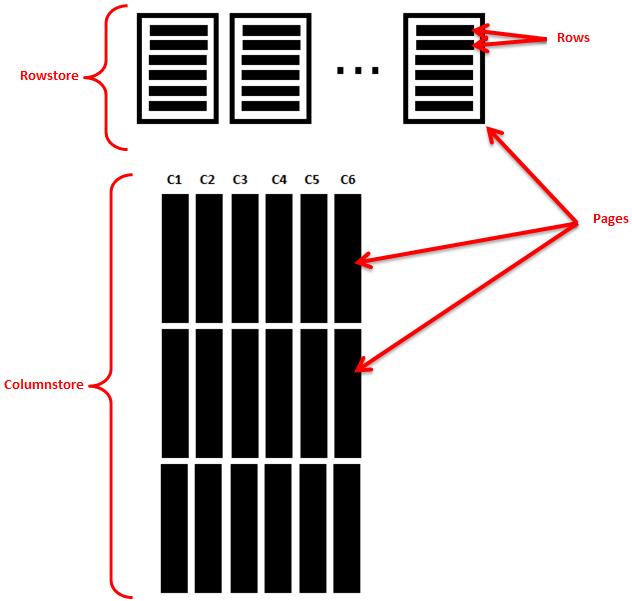
Whereas rowstore indexing shops a number of rows per web page, columnstore index shops every column in disk pages individually. The next picture illustrates the distinction between columnstore and rowstore indexing from storage perspective:
![clip_image001[14]](https://i0.wp.com/www.biinsight.com/wp-content/uploads/2013/08/clip_image00114.png?ssl=1 "clip_image001[14]")
As you possibly can see C1, C2…C6 are saved in numerous pages, so:
· solely the columns wanted in a question are fetched from the disk
· as a result of redundancy of information inside a column it’s simpler for information compression
· due to the info compression and ceaselessly accessed elements of generally used columns are nonetheless stay in reminiscence, therefore, buffer hit price is improved.
As mentioned, columnstore is working primarily based on xVelocity expertise that’s in widespread with SQL Server Evaluation Providers Tabular Mannequin in addition to PowerPivot. Really, it doesn’t imply that columnstore indexes have to slot in reminiscence; nonetheless, they will use obtainable server reminiscence successfully to maneuver parts of columns out and in of reminiscence on demand. As columnstore indexes retailer all information for separate columns in separate pages, utilizing columnstore indexes improves I/O scan efficiency considerably.
There are a number of advantages of utilizing columnstore indexes compared with rowstore indexes as beneath:
· As mentioned, solely the columns wanted in a question are fetched from the disk, so, the info warehouse question efficiency is approach sooner for widespread information warehouse queries
· As information is extremely compressed utilizing xVelocity expertise the disk house reduces successfully
· Because the pages are considerably compressed, the pages containing essentially the most ceaselessly accessed columns stay in reminiscence
· As batch mode processing that’s a sophisticated question execution expertise that processes chunks of columns is used, the CPU utilization is decreased.
Columnstore indexing is a brand new expertise, so, you need to be conscious of its restrictions if you’re planning to implement columnstore indexes. The next restrictions ought to be thought-about:
· Columnstore index is out there solely in SQL Server Enterprise, Developer and Analysis editions, so, you’ll face to the next error message if you wish to use columnstore index in different editions of SQL Server 2012: “CREATE INDEX assertion failed as a result of a columnstore index can’t be created on this version of SQL Server.”
· Tables containing columnstore indexes can’t be up to date. This restriction could be eliminated within the subsequent releases of SQL Server. Now, methods to insert, replace or delete information in a desk that comprises a columnstore index? There are three options for this function; nonetheless, plainly the primary resolution is extra easy than the others.
1. Drop the columnstore index, carry out any INSERT, UPDATE, DELETE or MERGE operations, and recreate the columnstore index.
2. Partition the desk and swap partitions. For a bulk insert:
§ insert information right into a staging desk
§ construct a columnstore index on the staging desk
§ swap the staging desk into an empty partition
For different updates:
§ swap a partition out of the primary desk right into a staging desk
§ disable or drop the columnstore index on the staging desk
§ carry out the replace operations
§ rebuild or re-create the columnstore index on the staging desk
§ swap the staging desk again into the primary desk.
3. Place static information right into a predominant desk with a columnstore index, and put new information and up to date information prone to change, right into a separate desk with the identical schema that doesn’t have a columnstore index. Apply updates to the desk with the newest information. To question the info, rewrite the question as two queries, one in opposition to every desk, after which mix the 2 outcome units with UNION ALL. The sub-query in opposition to the massive predominant desk will profit from the columnstore index. If the updateable desk is way smaller, the dearth of the columnstore index could have much less impact on efficiency. Whereas it’s also attainable to question a view that’s the UNION ALL of the 2 tables, it’s possible you’ll not see a transparent efficiency benefit. The efficiency will rely on the question plan, which can rely on the question, the info, and cardinality estimations. The benefit of utilizing a view is that an INSTEAD OF set off on the view can divert updates to the desk that doesn’t have a columnstore index and the view mechanism could be clear to the consumer and to purposes. When you use both of those approaches with UNION ALL, check the efficiency on typical queries and resolve whether or not the comfort of utilizing this method outweighs any lack of efficiency profit.
Word: As we mentioned, the tables containing columnstore index, can’t be up to date. However, it doesn’t appear to be a good suggestion to make use of columnstore to make a read-only desk. As a result of, columnstore index just isn’t designed for this specific function and it’s attainable that Microsoft removes this restriction within the subsequent releases of SQL Server.
· Columnstore indexes should not supporting greater than 1024 columns
· Solely nonclustered columnstore indexes can be found (there isn’t a clustered columnstore index)
· A columnstore index can’t be a novel index
· Creating columnstore indexes on a view or listed view just isn’t supported
· Columnstore indexes can not embody a sparse column (an bizarre column that has an optimized storage for null values)
· Columnstore indexes can not act as main keys or international keys (keep in mind that a columnstore index can’t be a novel index)
· Columnstore indexes can’t be modified utilizing “ALTER INDEX” assertion. Nonetheless, the “ALTER INDEX” assertion can be utilized to disable and rebuild a columnstore index. So the one method to modify a columnstore index is to drop and recreate the columnstore index.
· The key phrase “INCLUDE” just isn’t supported to create a columnstore index
· Sorting just isn’t allowed in a columnstore index, so, “ASC” and “DESC” key phrases should not supported. Really, columnstore indexes are ordered in accordance with the compression algorithm. Values chosen from a columnstore index could be sorted by the search algorithm, however you will need to use the ORDER BY clause to ensure sorting of a outcome set.
· A columnstore index doesn’t use and even preserve statistics as rowstore index does
· A columnstore index doesn’t assist FILESTREAM attribute, so, solely the columns within the desk that aren’t used within the columnstore index can comprise the FILESTREAM attribute.
· As column retailer index is optimized for in-memory processing, so, server reminiscence limitations ought to be thought-about
· Columnstore indexes don’t assist SEEK, so, if the desk trace FORCESEEK is used, the optimizer won’t think about the columnstore index.
· Columnstore indexes can’t be mixed with web page and row compression, as columnstore indexes are already compressed in a distinct format.
· Replication just isn’t supported for tables containing columnstore index
· Change monitoring and alter information seize should not supported
· Filestream just isn’t supported
· The next information varieties can’t be included in a columnstore index:
1. binary and varbinary
2. ntext , textual content, and picture
3. varchar(max) and nvarchar(max)
4. uniqueidentifier
5. rowversion (and timestamp)
6. sql_variant
7. decimal (and numeric) with precision larger than 18 digits
8. datetimeoffset with scale larger than 2
9. CLR varieties (hierarchyid and spatial varieties)
10. xml
Making a columnstore index is rather like creating every other index. Usually, there are two methods to create a columnstore index, creating index utilizing T-SQL statements or utilizing SSMS (SQL Server Administration Studio).
Making a columnstore index utilizing T-SQL
In a question editor window execute the next assertion:
CREATE NONCLUSTERED COLUMNSTORE INDEX IndexName
ON TableName (Column1, Column2, …)
Making a columnstore index utilizing SSMS
Open SQL Server Administration Studio (SSMS) and hook up with a SQL Server database engine. Keep in mind that columnstore index is out there simply in SQL Server 201 Enterprise Version.
1. From “Object Explorer”-> broaden the instance-> broaden the databases-> broaden the database-> broaden the table-> proper click on on “Indexes”-> New Index-> Non-Clustered Columnstore Index
![clip_image002[10]](https://i0.wp.com/www.biinsight.com/wp-content/uploads/2013/08/clip_image00210.png?ssl=1 "clip_image002[10]")
2. In “New Index” window-> Index Title (kind a reputation)-> Add-> choose the column-> OK-> OK
![clip_image004[8]](https://i0.wp.com/www.biinsight.com/wp-content/uploads/2013/08/clip_image0048.png?ssl=1 "clip_image004[8]")
Now the columnstore index is created and you’ll see it within the “Indexes” in object explorer.
![clip_image005[8]](https://i0.wp.com/www.biinsight.com/wp-content/uploads/2013/08/clip_image0058.png?ssl=1 "clip_image005[8]")
As columnstore index is a brand new expertise, it has many limitations and restrictions. Though the entire columnstore index restrictions ought to be thought-about, one of the vital common and essential restrictions of columnstore index is that it’s NOT obtainable in all variations of SQL Server 2012. So, it’s actually essential to know what model of SQL Server goes for use in manufacturing setting. In case your organisation just isn’t going to make use of SQL Server 2012 Enterprise version, you can not use columnstore index in any respect. So, it’s important to plan to create rowstore indexes in your information warehouse.
As a result of the truth that the indexing is basically associated to the queries, it ought to be investigated in a case by case foundation. Though columnstore indexing is enhancing the question efficiency, nonetheless, in some circumstances it can trigger poorer question efficiency.
Among the efficiency advantage of a columnstore index is derived from the compression strategies that cut back the variety of information pages that have to be learn and manipulated to course of the question. Compression works greatest on character or numeric columns which have massive quantities of duplicated values. For instance, dimension tables might need columns for postal codes, cities, and gross sales areas. If many postal codes are situated in every metropolis, and if many cities are situated in every gross sales area, then the gross sales area column could be essentially the most compressed, town column would have considerably much less compression, and the postal code would have the least compression. Though all columns are good candidates for a columnstore index, including the gross sales area code column to the columnstore index will obtain the best profit from columnstore compression, and the postal code will obtain the least.
References: SQL Server 2012 Books On-line, SQL Server Technical Article: Columnstore Indexes for Quick Information Warehouse Question Processing in SQL Server 11.0; November 2010