

{kind=link}
On this weblog publish, I’d prefer to introduce some fundamental ideas of reinforcement studying, some necessary terminology, and a easy use case the place I create a recreation taking part in AI in my firm’s analytics platform. After studying this, I hope you’ll have a greater understanding of the usefulness of reinforcement studying, in addition to some key vocabulary to facilitate studying extra.
Reinforcement Studying and How It’s Used
You could have heard of reinforcement studying (RL) getting used to coach robots to stroll or gently choose up objects; or maybe you’ll have heard of Deep Thoughts’s AlphaGo Zero AI, which is taken into account by some to be the perfect Go “participant” on this planet. Or maybe you haven’t heard of any of that. So, we’ll begin from the start.
WANT TO STAY IN THE KNOW?
Get our weekly e-newsletter in your inbox with the newest Knowledge Administration articles, webinars, occasions, on-line programs, and extra.
Reinforcement studying is an space of machine studying and has grow to be a broad subject of research with many alternative algorithmic frameworks. In abstract, it’s the try to construct an agent that’s able to deciphering its setting and taking an motion to maximise its reward.
At first look, this sounds much like supervised studying, the place you search to maximise a reward or decrease a loss as effectively. The important thing distinction is that these rewards or losses aren’t obtained from labeled knowledge factors however from direct interplay with an setting, be it actuality or simulation. This agent may be composed of a machine studying mannequin – both fully, partially, or by no means.
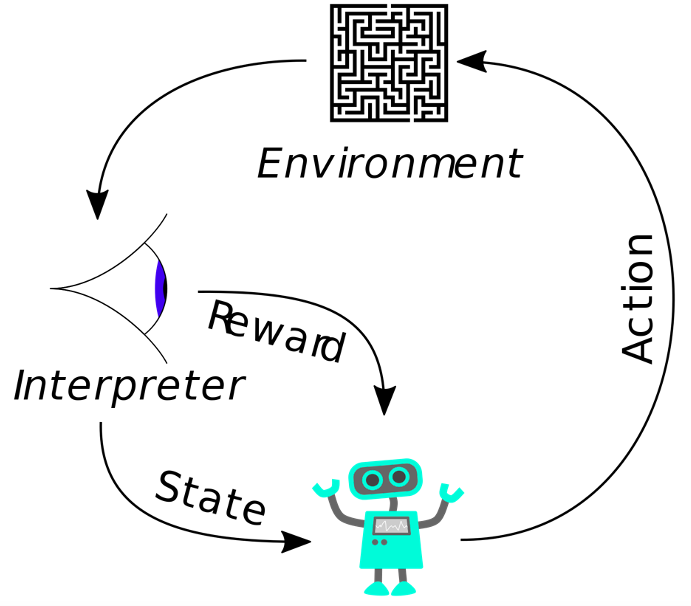
A easy instance of an agent that accommodates no machine studying mannequin is a dictionary or a look-up desk. Think about you’re taking part in “Rock-Paper-Scissors” in opposition to an agent that may see your hand earlier than it makes its transfer. It’s pretty easy to construct this look-up desk, as there are solely three attainable recreation states for the agent to come across.
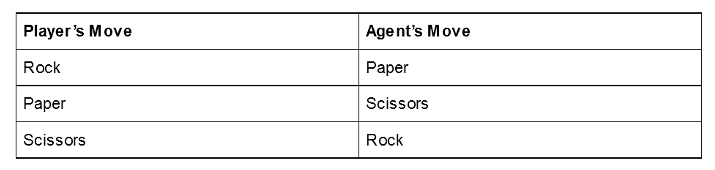
This may get out of hand in a short time, nevertheless. Even a quite simple recreation reminiscent of Tic-Tac-Toe has almost 10 million attainable board states. A easy look-up desk would by no means be sensible, and let’s not even discuss concerning the variety of board states in video games like Chess or Go.
This Is The place Machine Studying Comes into the Equation
Via totally different modeling strategies, generally neural networks – because of their iterative coaching algorithm – an agent can be taught to make choices primarily based on setting states it has by no means seen earlier than.
Whereas it’s true that Tic-Tac-Toe has many attainable board states and a look-up desk is impractical, it might nonetheless be attainable to construct an optimum agent with a number of easy IF statements. I take advantage of the Tic-Tac-Toe instance anyway, due to its easy setting and well-known guidelines.
Actual-World Functions of Reinforcement Studying
When speaking about reinforcement studying, the primary query is often “What’s that good for?” The examples above are very far faraway from most sensible use circumstances; nevertheless, I do need to spotlight a number of real-world purposes within the hopes of inspiring your creativeness.
- Chemical Drug Discovery: Reinforcement Studying is commonly used to create chemical formulation/compounds with a desired set of bodily properties, in line with the next sequence of actions: Generate compound > check properties > replace mannequin > repeat.
- Bayesian Optimization: Included within the Parameter Optimization Loop, this technique iteratively explores the parameter house and updates a distribution perform to make future choice choices.
- Visitors Mild Management: Reinforcement studying has made enormous strides right here as effectively. Nonetheless, on this case, the partially observable nature of real-world visitors provides some layers of complexity.
- Robotics: That is probably essentially the most well-known of those use circumstances. Specifically, we’ve seen many examples of robots studying to stroll, choose up objects, or shake fingers lately.
Even when none of those use circumstances hits near dwelling for you, it’s at all times necessary {that a} knowledge scientist regularly provides new instruments to his belt, and hopefully, it’s an fascinating subject apart from.
Including Formality
Let’s now lay out a extra concise framework.
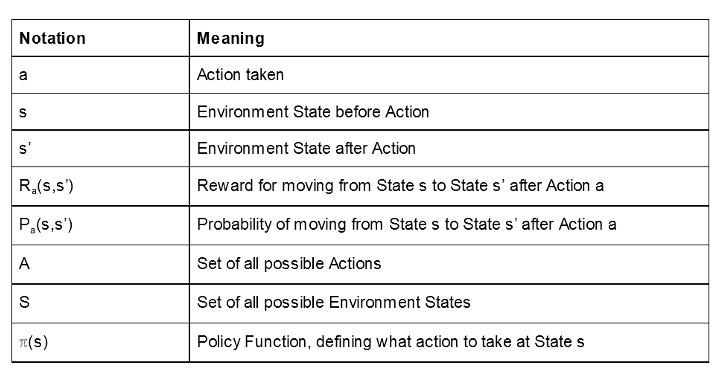
Primary reinforcement studying is described as a Markov Resolution Course of. This can be a stochastic system the place the chance of various outcomes relies on a selected Motion, a, and the present Setting State, s. Particularly, this end result is a New Setting State that we’ll denote s’.
Let’s outline two capabilities on high of those phrases as effectively: Ra(s,s’) and Pa(s,s’). Ra(s,s’) denotes the reward assigned when transferring from state s to state s’, and Pa(s,s’) the chance of transferring from state s to s’, given motion a.
So, we’ve outlined the system, however we’re nonetheless lacking one half. How will we select the Motion we should always take at State s? That is decided by one thing referred to as a Coverage Operate denoted as ℼ(s). Some easy examples of a Coverage Operate is perhaps:
- ℼ(s) = transfer up
- ℼ(s) = hit me
- ℼ(s) = a; the place a is a random component of A
- when utilizing a machine studying mannequin for ℼ(s) we might begin from this level to achieve a various knowledge set for future trainings
A Coverage Operate could possibly be far more difficult as effectively. Resembling an enormous set of nested IF statements … however let’s not go there.
What We’ve Accomplished So Far
1. Decide motion to take on the present State s
2. Decide New State s’
- This new state is commonly stochastic, primarily based on Pa(s,s’)
3. Decide the Reward to be assigned to motion a
- Reward relies on some perform Ra(s,s’) relying on the chosen motion a. For instance, there’s some intrinsic reward if I get to work within the morning, however far much less if I selected to constitution a helicopter to take me there …
Selecting a Coverage Operate
Let’s discuss extra concerning the Coverage Operate ℼ(s). There’s a myriad of choices for ℼ(s), when utilizing machine studying, however for the sake of this text, I need to introduce one easy instance: An agent I’ve constructed to play Tic-Tac-Toe.
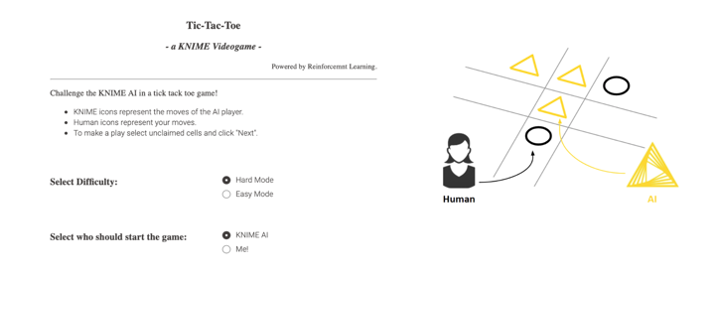
I discussed above that for Tic-Tac-Toe, there are far too many board states to permit for a look-up desk. Nonetheless, at any given State, s, there are by no means greater than 9 attainable Actions, a. We’ll denote extra concisely these attainable actions at state s as As, contained in A. If we knew what the reward could be for every of those attainable actions, we may outline our Coverage Operate to provide the motion with the very best reward, that’s:
ℼ(s) = a | Maxa∈As Ra(s, s’)
Reward Operate
Among the many many attainable reward capabilities, we will select to quantify how near profitable – or dropping – the transfer introduced the Agent. One thing like:
Ra(s,s’) = 0.5 + [# of Moves played so far] / 2*[# of Moves in game] if Agent wins
0.5 – [# of Moves played so far] / 2*[# of Moves in game] if Agent loses
Nonetheless, this reward perform is undetermined till the sport is over and the winner turns into identified. That is the place we will apply machine studying: We are able to prepare a predictive mannequin to estimate our reward perform, implicitly predicting how shut this transfer will take the agent to win. Specifically, we will prepare a neural community to foretell the reward given some motion. Let’s denote this as:
NN(a) ~ Ra(s,s’)

Neural Community Coaching – Supervised Studying
At this level, the issue has moved to the coaching of a neural community, which is a supervised studying downside. For that, we want a coaching set of labeled knowledge, which we will accumulate by merely letting our community play the sport. After each recreation has been performed, we rating all of the actions, by means of the unique Reward Operate Ra(s,s’). On these scores on the actions in all performed video games, we then prepare a neural community to foretell the reward worth – NN(a) – for every motion in the course of the sport.
The community is skilled a number of occasions on a brand new coaching set together with the newest labeled video games and actions. Now, it does take lots of knowledge to successfully prepare a neural community, or at the least greater than we’d get from only one or two video games. So how can we accumulate sufficient knowledge?

As a closing theoretical hurdle, it ought to be famous that neural networks are, sometimes, deterministic fashions and, if left to their very own gadgets, will at all times make the identical predictions given the identical inputs. So, if we go away the agent to play in opposition to itself, we’d get a sequence of an identical video games. That is unhealthy, as a result of we wish a various set of knowledge for coaching. Our mannequin gained’t be taught a lot, if it at all times performs the very same recreation transfer after transfer. We have to power the community to “discover” extra of the transfer house. There are definitely some ways to perform this, and one is to change the coverage perform at coaching time. Now as a substitute of being:
ℼ(s) = a | Maxa∈As NN(a)
It turns into the next, which allows the agent to discover and be taught:
ℼ(s) = a | Maxa∈As NN(a) with chance 0.5
= a ∈ As with chance 0.5
A standard strategy is to change the above possibilities dynamically, sometimes lowering them over time. For simplicity I’ve left this as a relentless 50/50 break up.
Implementation
Now for the implementation! We have to construct two purposes: one to coach the agent and one to play in opposition to the agent.
Let’s begin with constructing the primary software, the one which collects the info from user-agent video games in addition to from agent-agent video games, labels them by calculating the rating for every motion, and makes use of them to coach the neural community to mannequin the reward capabilities. That’s, we want an software that:
- Defines the neural community structure
- Implements the reward perform Ra(s,s’), as outlined within the earlier part, to attain the actions
- Implements the newest adopted coverage perform ℼ(s)
- Lets the agent play in opposition to a consumer and saves the actions and results of the sport
- Lets the agent play in opposition to itself and saves the actions and results of the sport
- Scores the actions
- Trains the community
For the implementation of this software we used my firm’s analytics platform, as a result of it’s primarily based on a Graphical Person Interface (GUI) and it’s straightforward to make use of. The platform extends its user-friendly GUI additionally to the Deep Studying Keras integration. Keras libraries can be found as nodes and may be carried out with a easy drag and drop.
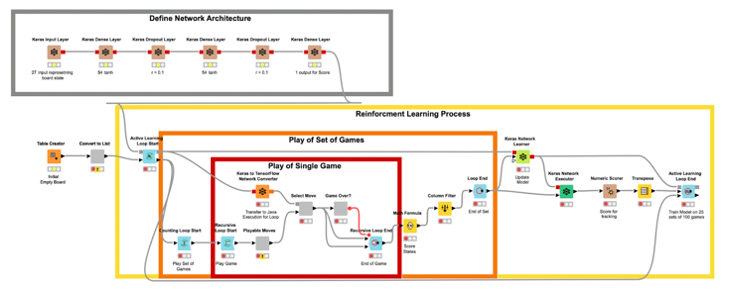
The Community Structure
Within the workflow in Fig. 5, the brown nodes, the Keras nodes, on the very high construct the neural community structure, layer after layer.
- The enter layer receives a tensor of form [27] as enter, the place 27 is the dimensions of the board state. The present state of the board is embedded as a one-hot vector of dimension 27.
- The output layer produces a tensor of form [1] because the reward worth for the present motion.
- The center 2 hidden layers, with 54 items every, construct the totally linked feedforward community used for this job. These 2 layers have a dropout perform, with a ten% charge, utilized to assist counter overfitting because the mannequin continues to be taught.
Implementing the Recreation Classes
Within the core of the workflow, you see three nested loops: a recursive loop inside a counting loop inside an lively studying loop. These signify, from inside to exterior, the play of a person recreation (the recursive loop), the play of a set of video games (the counting loop), and the play of many units of video games in between coaching classes of the community (the lively studying loop).
The recursive loop regularly permits the community to make strikes on the sport board, from alternating sides, till an finish situation is met. This situation being: three marks in a row, column, or diagonal required to win a recreation of Tic-Tac-Toe, or if the board is stuffed fully within the occasion of a draw.
The counting loop then information the totally different recreation states, in addition to how shut they had been to both profitable or dropping, and repeats the method 100 occasions. It will produce 100 video games price of board states we’ll use to coach the Community earlier than repeating the method.
The lively studying loop collects the sport classes and the board states from every recreation, assigns the reward rating to every motion, as carried out within the Math System node, and feeds the Keras Community Learner node to replace the community with the labeled knowledge, exams the community, after which waits until the subsequent batch of knowledge is prepared for labeling and coaching. Word that the testing shouldn’t be required for the educational course of however is a option to observe the fashions progress over time.
The lively studying loop is a particular type of loop. It permits us to actively receive new knowledge from a consumer and label them for additional coaching of machine studying fashions. Reinforcement studying may be seen as a selected case of lively studying, since right here knowledge additionally should be collected by means of interactions with the setting. Word that it’s the recursive use of the mannequin port within the loop construction that permits us to repeatedly replace the Keras mannequin.
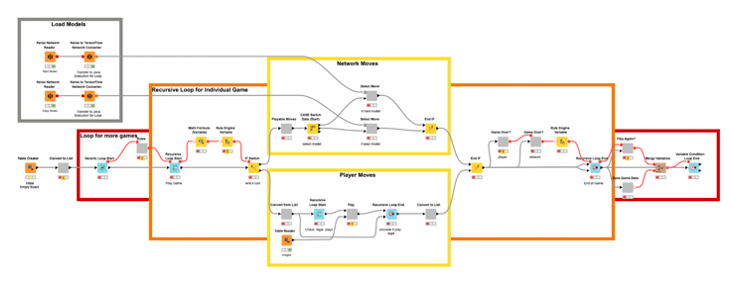
Agent-Agent Recreation Classes
On this workflow, the agent performs in opposition to itself a configured variety of occasions. By default, the community performs 25 units of 100 video games for a complete of two,500 video games. That is the Straightforward Mode AI accessible within the WebPortal. The Arduous Mode AI was allowed to play a further 100 units of 100 video games a complete of 12,500 video games. To additional enhance the AI, we may tune the community structure or play with totally different reward capabilities.
The Recreation as a Internet Software
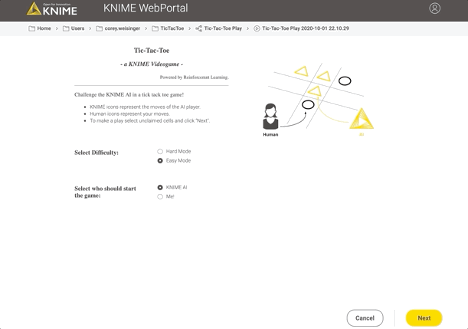
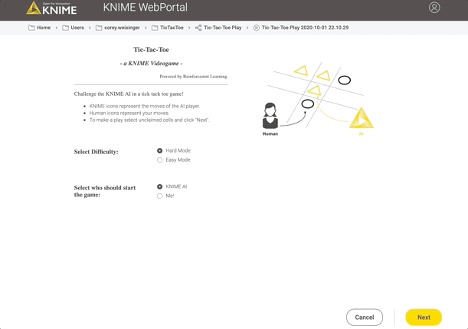
The second software we want is an online software. From an online browser, a consumer ought to be capable of play in opposition to the agent. To deploy the sport on an online browser we use the WebPortal, a function of the Server.
In the Analytics Platform, JavaScript-based nodes for knowledge visualization can construct elements of net pages. Encapsulating such JavaScript-based nodes into elements permits the development of dashboards as net pages with totally linked and interactive plots and charts. Specifically, we used the Tile View node to show every of the 9 sections of the Tic-Tac-Toe board, and present a clean, human, or KNIME icon on every.
The deployment workflow that permits a human to play (and additional prepare) the agent is proven in Fig. 6. A recreation session on the ensuing web-application is proven in Fig. 7.
This instance of each the studying and taking part in workflows is out there so that you can obtain, play with, and modify on the Hub! I’m curious to see what enhancements and use case variations you may include.
Obtain these workflows from the Hub right here:
Conclusion
In abstract, we launched a number of fashionable use circumstances for reinforcement studying: drug discovery, visitors regulation, and recreation AI. On that subject, I encourage you to take to Google and see the numerous different examples.
We launched a easy reinforcement studying technique primarily based on the Markov Resolution Course of and detailed some key notation that may enable you in your individual analysis. Lastly, we lined how a easy instance may be carried out in my firm’s Analytics Platform.
Initially printed on the KNIME weblog.